Last updated on
Apr 10, 2026
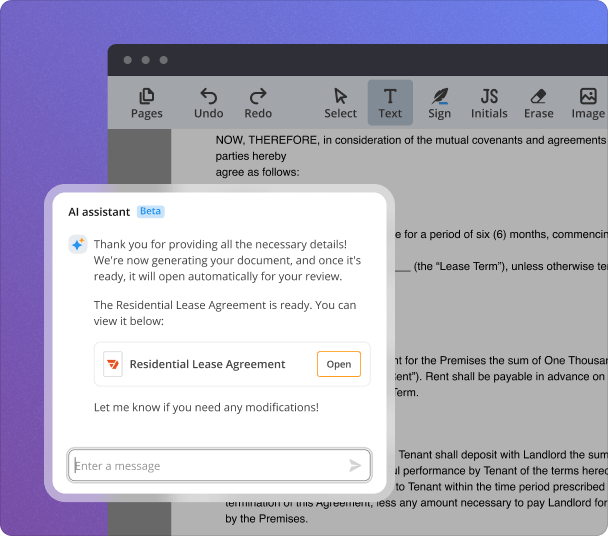
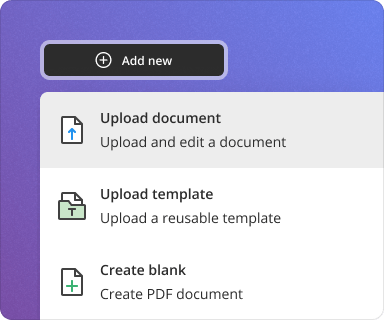
Generate anything — from proposals and reports to contracts and NDAs — with just a few quick prompts. Save time and avoid the hassle of starting from scratch.
Extracting data from a cover template refers to the process of pulling relevant information from a template designed for document covers, typically involving fields like titles, subtitles, author names, dates, and other metadata. This task is crucial for ensuring that the documents are organized and have clear identification, which greatly aids in document management and retrieval.
Using AI-powered tools like pdfFiller to extract data from cover templates simplifies and accelerates document workflows. AI automates the identification and extraction of necessary information, reducing manual effort and increasing accuracy, thereby contributing to enhanced productivity. Furthermore, businesses can maximize their operational efficiency as documents are processed in real-time.
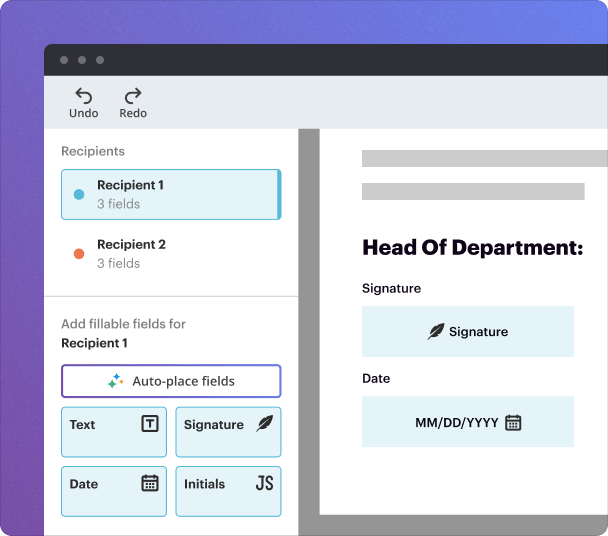
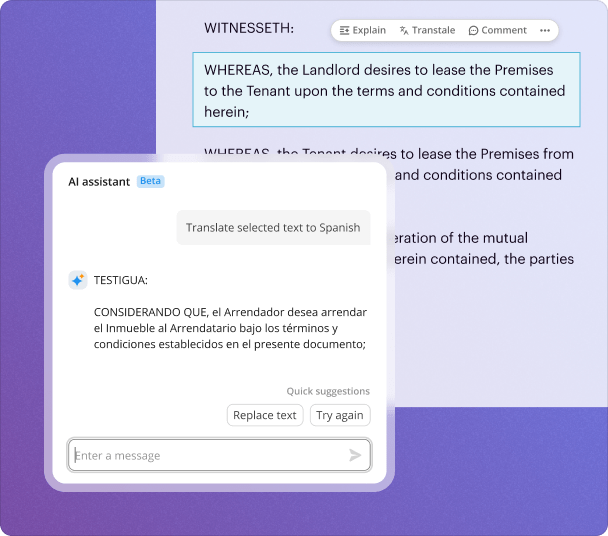
pdfFiller integrates AI capabilities that facilitate the extraction of data from cover templates efficiently. Some key features include intelligent data recognition, customizable templates, and comprehensive document management solutions.
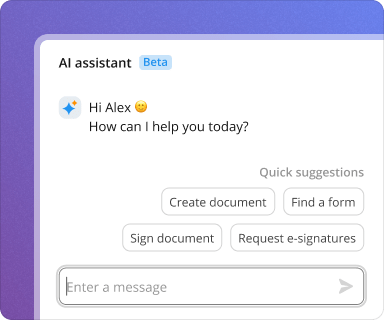
Extracting data from a cover template using pdfFiller is a straightforward process. Follow this step-by-step guide to harness the power of AI.
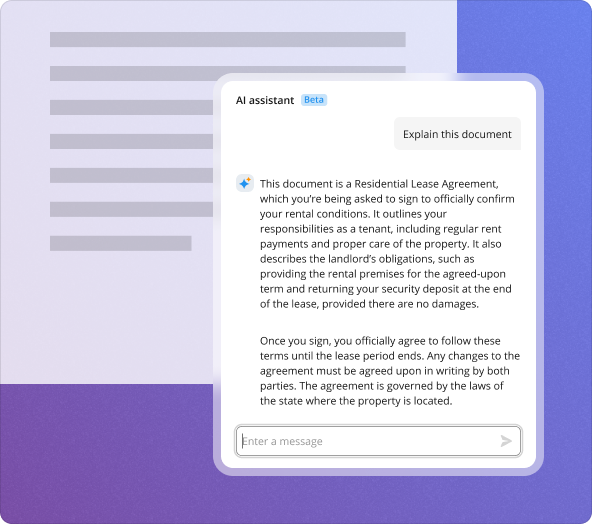
After extracting data from a cover template, it's essential to review and refine the AI-generated outputs to ensure accuracy. Best practices include verifying each extracted field, comparing it with the original document, and making necessary adjustments. It's also beneficial to utilize pdfFiller's editing tools to enhance or format the data before finalizing it.
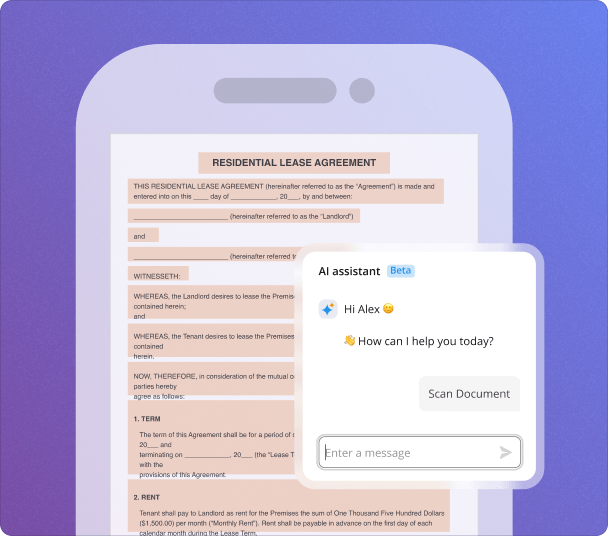
Sharing and distributing documents made easier with AI-driven data extraction is simple with pdfFiller. Users can easily share finalized documents via email, link, or directly through integrated platforms. This seamless sharing capability saves time and ensures that all collaborators have access to the most current versions.
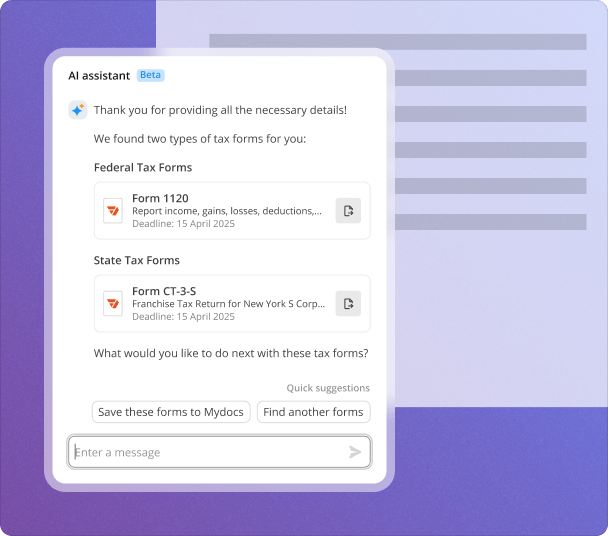
Many industries leverage AI data extraction to streamline their workflow. Common use cases include academic institutions for managing thesis submissions, publishing houses for manuscript handling, legal sectors for contracts, and corporate environments for project documentation.
While various AI-powered tools are available for document management, pdfFiller stands out for its ease of use and integration capabilities. Unlike some competitors, pdfFiller not only focuses on data extraction but also emphasizes comprehensive document management, such as eSigning and collaborative editing, making it a more rounded choice for organizations.
In essence, extracting data from a cover template with an AI-powered tool like pdfFiller transforms the document creation process by enhancing efficiency, accuracy, and collaboration. By utilizing pdfFiller's robust functionalities, users can streamline their workflow and focus on what truly matters - growing their business.